I have talked a lot about voiced sounds in previous posts, but I have been ignoring one cool thing that you can do to trick your brain into hearing something unexpected. Before we can get to that though, I need to teach you about voice onset time.
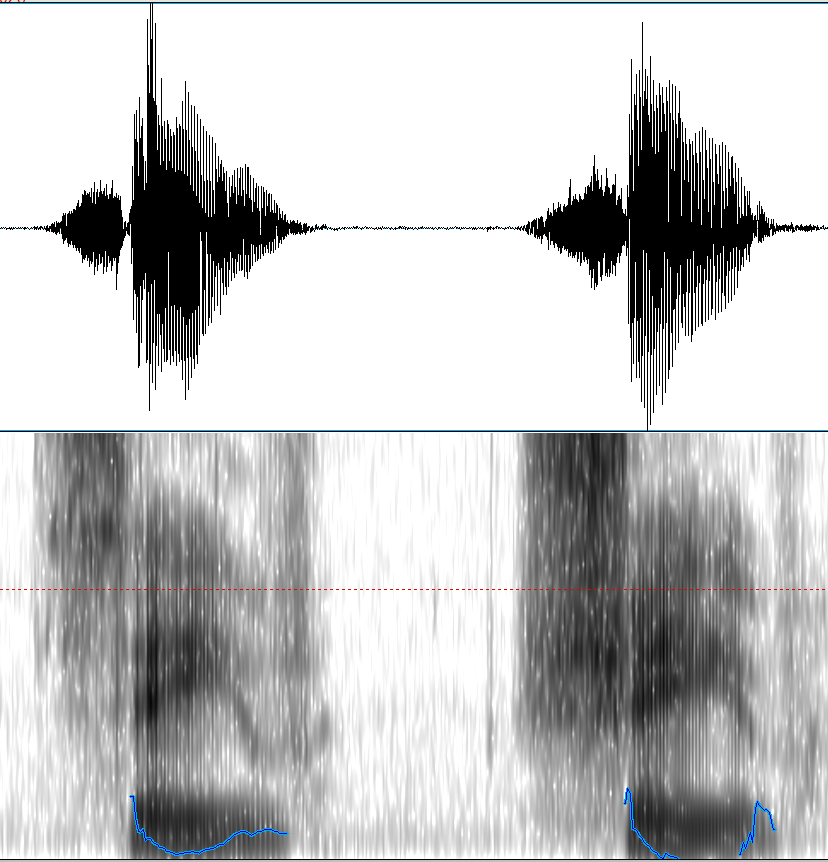
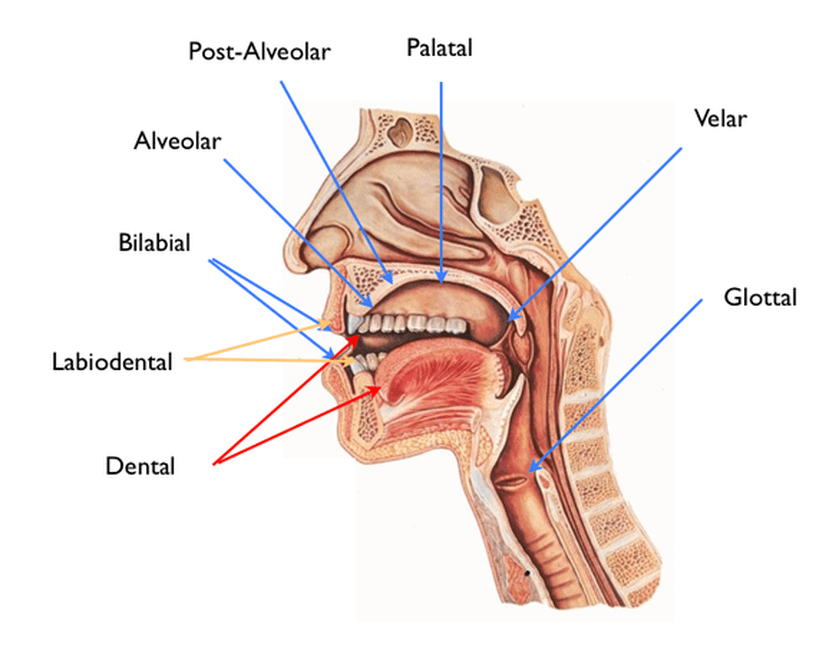
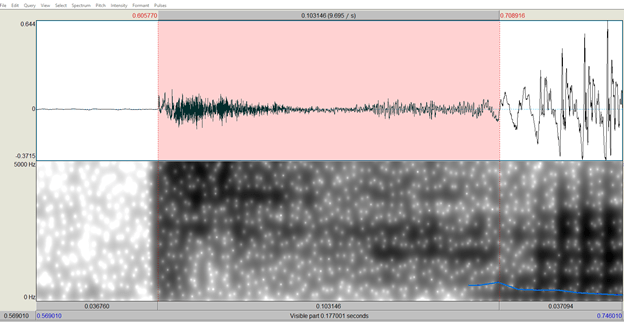
Voice onset time (or VOT) is a phonetic measurement of how long it takes for voicing to start after a stop is released. When you are articulating a stop, you are using either your lips (for [p] and [b]) or your tongue (for all other stops like [t] [d] [k] and [g]) to completely cut off the flow of air momentarily in speech (hence the name stop). The stoppage of airflow in a stop occurs at the beginning of the sound which leads to an air pressure buildup behind the lips or tongue that is audibly released when the sound is produced (this is called the release burst). If you have a word with a stop at the beginning of it like “dog”, we can measure the amount of time between when the stop is released (when air starts flowing again) and when the vocal folds start vibrating again. This does require using some audio analysis software (Praat) to see clearly, but here is what it looks when I say “dog”.

You can see on the left side of this wave form where there is no sound. This is because my tongue is placed against my alveolar ridge and there is no air or sound coming out yet. The dark black line at the left edge of the highlighted region (in pink) is the point where my tongue releases from that position and the air begins to flow out producing sound. This is not when the vocal folds start vibrating though. That point comes approximately 15 milliseconds later (shown at the right side of the highlighted area).
This 15 millisecond VOT is slightly higher than average. The average VOT for voiced stops like “d” in English is anywhere from 0-10 milliseconds.
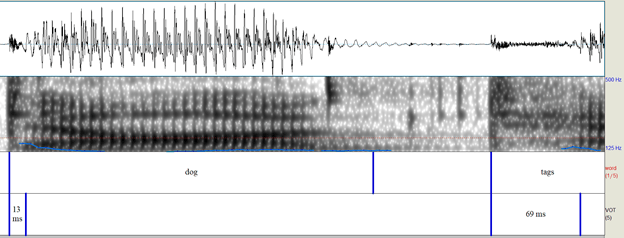
Now take a look at this recording of me saying the word “tag”.
Visually, you can see that the VOT for “tag” is much larger coming in at about 103 milliseconds. Again, this is higher than the expected average of about 30-40 milliseconds, but we can chalk this up to the productions being recorded in isolation with careful and purposeful speech.
If I record the two words together in a spoken sentence like “the soldier is wearing dog tags” it becomes a little closer to the expected averages as seen in this third image here.
What is making the VOT so much larger for a “t” compared to a “d”? The “t” sound in English is a voiceless stop meaning that the consonant itself is articulated with the vocal folds spread so they do not vibrate. So, when we are measuring the VOT of a voiceless sound, we are measuring the time from when the stop is released to the beginning of the voicing from the adjacent vowel (all vowels are voiced). Contrast this with a “d” sound which is voiced stop meaning that the vocal folds are pressed together so that they vibrate during the actual consonant sound. With a voiced stop, we are measuring the time from when the stop is released until the vocal folds begin vibrating because of the consonant itself. We always expect voiceless stops to have a larger VOT than voiced stops for this reason and this is universal for all languages.
So is that all there is to VOT in English? It turns out that we have two types of voiceless stops in English. The one that you get will depend on the surrounding environment. Let’s do a little demo and you will see why I mean.
Place your hand in front of your mouth and say the word “stop”, and then, with your hand still in place, say the word “top” (Pandemic note: masks do interfere with this demonstration and will need to be removed for full effect). You will feel that when you say the word “top”, there is a significant puff of air that hits your hand compared to when you say the word “stop”. The burst of air is called aspiration, and in English, voiceless stops that appear at the beginning of a stressed syllable will have aspiration if they are the first sound. When we transcribe these aspirated stops in the International Phonetic Alphabet, we will use a superscript “h” to denote this aspiration [th].
In a word like “stop”, we have a voiceless unaspirated stop and these will have a VOT that is shorter than the aspirated version, but still longer than voiced stops like a “d” sound. Taking a look at one final recording of mine, when I say the word “stop” my VOT comes out at about 23 milliseconds.
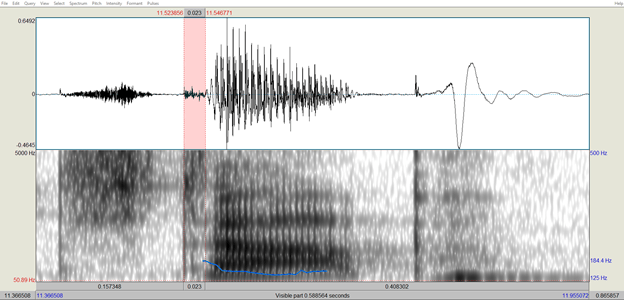
For English speakers, we don’t care about this distinction between aspirated and unaspirated voiceless stops. Both of these are just considered “t” sounds in our language. This is evidenced by the fact that you probably didn’t know about this difference. More importantly, if you say the word stop, but you put a lot of effort into really making sure that you get as much aspiration as possible on the “t”, it is still just the word “stop”. Nothing will change about the meaning of it.
This is not the case for all languages. Let’s take Armenian for instance. Armenian has a three way stop contrast where using a voiced stop, a voiceless unaspirated stop, or a voiceless aspirated stop in a word can change the meaning of it. An example from a 2003 paper states that the word transcribed as [baɹi] (the upside-down r is just a regular “r” sound) means ‘good’, the word [paɹi] means ‘dance’ while the word [phaɹi] refers to the first fruit that a tree bears. (Hacopian, N. (2003). A three-way VOT contrast in final position: data from Armenian. Journal of the International Phonetic Association, 33(1), 51–80. http://www.jstor.org/stable/44526902)
I think this is a really cool distinction that shows just how important language really is. Something as simple as how much aspiration you use to say a word can have a huge impact on the meaning of it. There are even some languages that will go the extra mile on their voiced stops and have what is referred to as pre-voicing. Pre-voicing means that the vocal folds will start vibrating before the stop articulation is released meaning that the VOT of that sound will end up being negative. This is a phenomenon that is observed in some Southern African languages such as Taa and !Kung.
And now for one last cool thing I can show you before I close out. Check out this video of a quick auditory illusion.
This is again, me saying the word “stop”. But if you notice from the second time it is played, when the “s” part of it is cut off, it sounds a little bit like a mixture between “top” and “dop”. This confusion you may be experiencing comes from the fact that a voiceless unaspirated stop is closer in VOT to a voiced stop than it is to a voiceless aspirated stop that we would expect at the beginning of the word “top”. Our brain wants to hear the word “top” and will ultimately recognize it as such, but there is this brief moment of ‘wot in tarnation’ that our brains go through first because we are pretty sure that might be a ”d”, even though “dop” is not a word.
Anyway, I am going long again, like usual. Thank you so much for sticking with this long-winded post. I hope this was informative and interesting to you. Be sure to come back next week for more interesting linguistic insights. If you have any topics that you want to know more about, please reach out and I will do my best to write about them. In the meantime, remember to speak up and give linguists more data.